
This is the first in a series of posts that detail our CodeHawk Analysis Platform's capabilities to help discover, understand, and remediate (with or without vendor intervention) vulnerabilities on production stripped binaries. The posts will focus on our research on CVE 2024-12248, a buffer overflow vulnerability in the Contec CMS 8000 Patient Monitor. This was work performed as part of our AMdP research project, funded by ARPA-H's DigiHeals program. The AMdP team (STR, Aarno Labs, and Vector 35) was responsible for identifying and disclosing CVE-2024-12248. The vulnerable code location was previously reported as only causing a denial of service on the device and was never addressed by the vendor. Through our research, we a) found that full RCE was possible, and b) were able to produce a validated binary patch that includes a verified fix of the vulnerability and provides assurances that no device functionality was affected as a result of the patch.
In this post, we will use the CodeHawk C analyzer to discover potential vulnerabilities in a lifting-to-valid-C-code of the vulnerable stripped binary as generated by the CodeHawk Binary analyzer. Follow-up posts in this series will cover how lifting is generated, how we enable targeted, minimally invasive binary patches to remediate critical vulnerabilities, and our capabilities for analyzing vendor-provided patches.
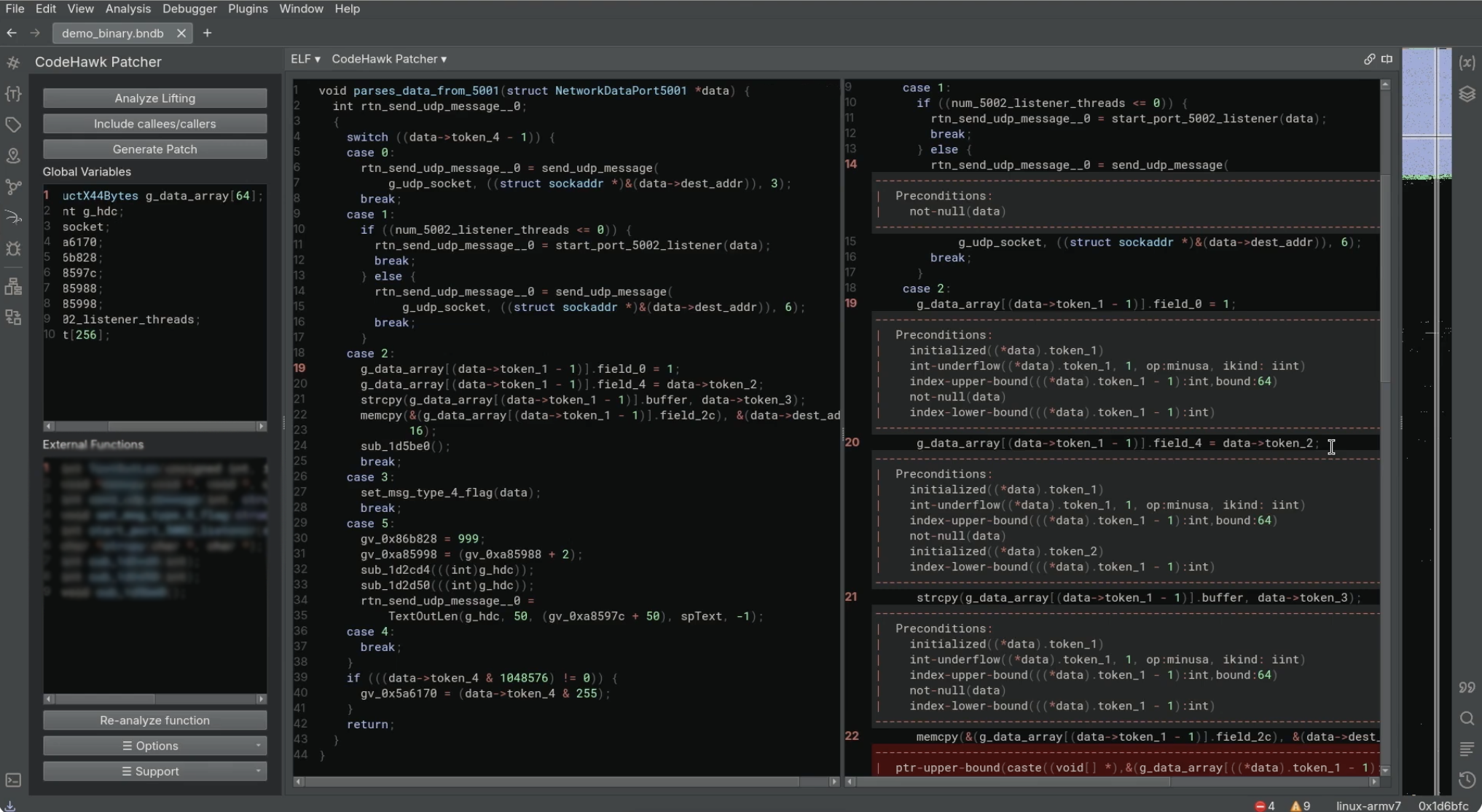
The CodeHawk C Analyzer, as applied to liftings, is available as a workflow in our CodeHawk BinaryNinja Plugin; see the screen capture below. If interested in using CodeHawk, please contact Aarno Labs.
Background
The CodeHawk-C analyzer is a sound static analyzer that focuses on analyzing potential undefined behavior. Memory safety, or the lack thereof, is a category of semantics that is captured by finding undefined behaviors.
CodeHawk identifies potential undefined behaviors using a multistep process: First, it generates proof obligations for all code constructs based on the C language specification. These proof obligations state the conditions that must be true for there to be no undefined behavior. Then, it iteratively uses abstract interpretation to generate invariants for the C code, and uses the generated invariants to prove these conditions valid in the program.
At the end of this process, the remaining open proof obligations indicate that insufficient evidence is present in the code to prove their safety. In some cases, CodeHawk will strengthen an open proof obligation and mark it as a violation. These are cases where data involved in the proof obligation is controlled by user input, and a value can be generated that leads to undefined behavior.
The generation of proof obligations proceeds in two stages. In the first stage, proof obligations are generated for all program constructs that can lead to undefined behavior, including library functions. These proof obligations are referred to as primary proof obligations. They are generated automatically at the start of the analysis and remain unchanged. The remainder of the analysis attempts to prove these primary proof obligations, which may lead to the generation of function preconditions, or API assumptions, where the responsibility for the safety of a proof obligation is transferred to the caller of a function, thus making the analysis context sensitive. These function preconditions automatically generate the corresponding proof obligations for the caller, known as supporting proof obligations. An example of this will be shown later in this post. A similar mechanism exists for proof obligations transferred to callees and supporting proof obligations for function postconditions.
Vulnerability Discovery and Analysis
We name the two functions involved in CVE-2024-12248 port_5001_listener and parses_data_from_5001. In the following discussion, we also refer to these functions as the listener and the parse function, respectively.
Parse Function
Analysis of the parse function shows 169 primary proof obligations, of which 15 are open. 33 of the proof obligations are delegated to the function's API. Our main focus will be on these delegated proof obligations. The relevant C statements and associated proof obligations are as follows:
215 g_data_array[(data->token_1 - 1)].field_0 = 1;
---------------------------------------------------------------------------
index-lower-bound(((*data).token_1 - 1):int) (safe)
condition index-lowerbound(((data->token_1 - 1):int) delegated to the api
index-upper-bound(((*data).token_1 - 1):int,bound:64) (safe)
condition index-upperbound(((data->token_1 - 1):int,64) delegated to the api
---------------------------------------------------------------------------
216 g_data_array[(data->token_1 - 1)].field_4 = data->token_2;
---------------------------------------------------------------------------
index-lower-bound(((*data).token_1 - 1):int) (safe)
condition index-lowerbound(((data->token_1 - 1):int) delegated to the api
index-upper-bound(((*data).token_1 - 1):int,bound:64) (safe)
condition index-upperbound(((data->token_1 - 1):int,64) delegated to the api
---------------------------------------------------------------------------
217 strcpy(g_data_array[(data->token_1 - 1)].buffer, data->token_3);
---------------------------------------------------------------------------
index-lower-bound(((*data).token_1 - 1):int) (safe)
condition index-lowerbound(((data->token_1 - 1):int) delegated to the api
index-upper-bound(((*data).token_1 - 1):int,bound:64) (safe)
condition index-upperbound(((data->token_1 - 1):int,64) delegated to the api
---------------------------------------------------------------------------
218 memcpy(&(g_data_array[(data->token_1 - 1)].field_2c), &(data->dest_addr), 16);
---------------------------------------------------------------------------
index-lower-bound(((*data).token_1 - 1):int) (safe)
condition index-lowerbound(((data->token_1 - 1):int) delegated to the api
index-upper-bound(((*data).token_1 - 1):int,bound:64) (safe)
condition index-upperbound(((data->token_1 - 1):int,64) delegated to the api
---------------------------------------------------------------------------The vulnerable part in all of these four statements is the use of data->token_1 (decremented by 1) as the index in the global array g_data_array. The proof obligations state that the index value, data->token_1 - 1 must be non-negative (index-lower-bound condition) and must be less than 64, the declared size of the array (index-upper-bound condition). No local information in the function is present that can prove that these requirements are met, because there are no bounds checks anywhere in the function.
However, with the use of invariants, it is established that the value of data->token_1 is entirely determined externally to this function, by the caller that passes the data argument to this function. This is why the status of the proof obligation is marked as safe: the responsibility for its safety can be fully transferred to the callers. This transfer is automatic and is reflected in the justification of the proof obligations. The transfer is accomplished by converting the proof obligation to a function precondition, as shown below, which is then used as the source for the supporting proof obligations:
api assumptions
17 index-lower-bound(((*data).token_1 - 1):int)
18 index-upper-bound(((*data).token_1 - 1):int,bound:64)
Listener Function
We now analyze the listener function, which is the caller of the parsing function, and where the structure fields used by the parsing function are constructed from network data received by the patient monitor. The function has 340 primary proof obligations. 51 of these are open, i.e., could not be proven safe. There are 8 supporting proof obligations, four of which are open, and all are marked as violations. All of these violations are shown for the call to the parsing function. The call and these supporting proof obligations are presented by the C Analyzer as follows:
316 parses_data_from_5001(&(parsed_data));
-------------------------------------------------------------------
<*> index-upper-bound(((*&(parsed_data)).token_1 - 1):int,bound:64) (violation)
return value from atoi may be tainted:
choose value: 2147483647 to violate safety constraint:
<*> index-lower-bound(((*&(parsed_data)).token_1 - 1):int) (violation)
return value from atoi may be tainted:
choose value: -2147483648 to violate the zero lower bound
<*> int-underflow((*&(parsed_data)).token_4, 1, op:minus, ikind: int) (violation)
result of subtraction: -2147483649 violates safe LB: -2147483648
(return value from atoi may be tainted:
choose max value: -2147483648; constant value: 1)
<*> int-underflow((*&(parsed_data)).token_1, 1, op:minus, ikind: int) (violation)
result of subtraction: -2147483649 violates safe LB: -2147483648
(return value from atoi may be tainted:
choose max value: -2147483648; constant value: 1)We can focus on the first two of these violated proof obligations: an index-upper-bound and index-lower-bound violation on the token_1 field. The analyzer output shows that the violations enable an attacker to write to an arbitrary address without any restrictions. The upper bound address is unbounded: choose value: 2147483647 to violate safety constraint and the lower bound address is unbounded: choose value: -2147483648 to violate the zero lower bound.
Severity
At this point, knowing that the caller of this function does not perform any checks either, and even worse, uses tainted data for data->token_1, we can judge the severity of the vulnerability. This vulnerability essentially allows an attacker to write data of their choosing to any location in memory of their choosing. And indeed, one of our partners in the AMdP team developed a RCE PoC as part of the disclosure process. Thus, a patch for this vulnerability is highly desirable!